反向代理缓存加速
学校要求毕业前要修满一门2学分的国际课程。所谓国际课程,就是英语授课,和专业相关,讲授前沿内容,课程的名字让人一听就决得很高大上、很Sci-fi 反正很水就是了 。
最后选择了名为 “Computational Biochemistry” 的课,实验课上要求按照网页上的教程练习 VMD 、Vim等软件。实验课上,就是连接到服务器,传文件,然后复制、粘贴,回车,报错。
当我打开老师的网站,直接傻眼了:
-
网站的网址很长,使用了.cn的域名。(当然这个其实无所谓。)
-
左上角显示了不安全,外加一个感叹号。网站没有https连接,没有SSL证书,明文传输,容易被劫持

-
主页的图片很大,加载很慢,从上到下,一段一段地加载
后来老师说,搭建网站的服务器带宽只有 1M。1M的带宽,要供40多位同学访问,图片不卡才怪。
实验课上要阅读教程,复制代码在服务器上运行。教程里图片挺多的,图片加载明显卡顿。为了避免实验课上慢人一步,就萌生了这个想法:自建反向代理+静态缓存来加速老师的教学网站。
用户不直接访问网站主机,而是访问反向代理服务器,透过代理服务器去访问网站。代理服务器可以缓存网站的静态文件,如html, png, js等。这些文件在一定时间内不会改变,因此下一次访问相同的文件,代理服务器直接返回给用户,不再向源服务器请求。如果反向代理服务器的带宽很大(比如放在宿舍的软路由),流量经过大带宽服务器代理,就减轻了源服务器的带宽压力。
以下教学网站简称源站,代理网站简称“反代”。浏览器访问反代后发现缓存过期或不存在,反代向源站请求资源,简称“回源”。
很显然,为了加速源站,实现网页秒开,反代必须要尽可能缓存源站的所有文件,并设置较长的过期时间。
1panel设置
在服务器的设置之前,需要在添加一条DNS记录给反代使用。
这里使用1panel进行网站的配置:
创建网站,选择反向代理,填入自己的域名和源站地址:
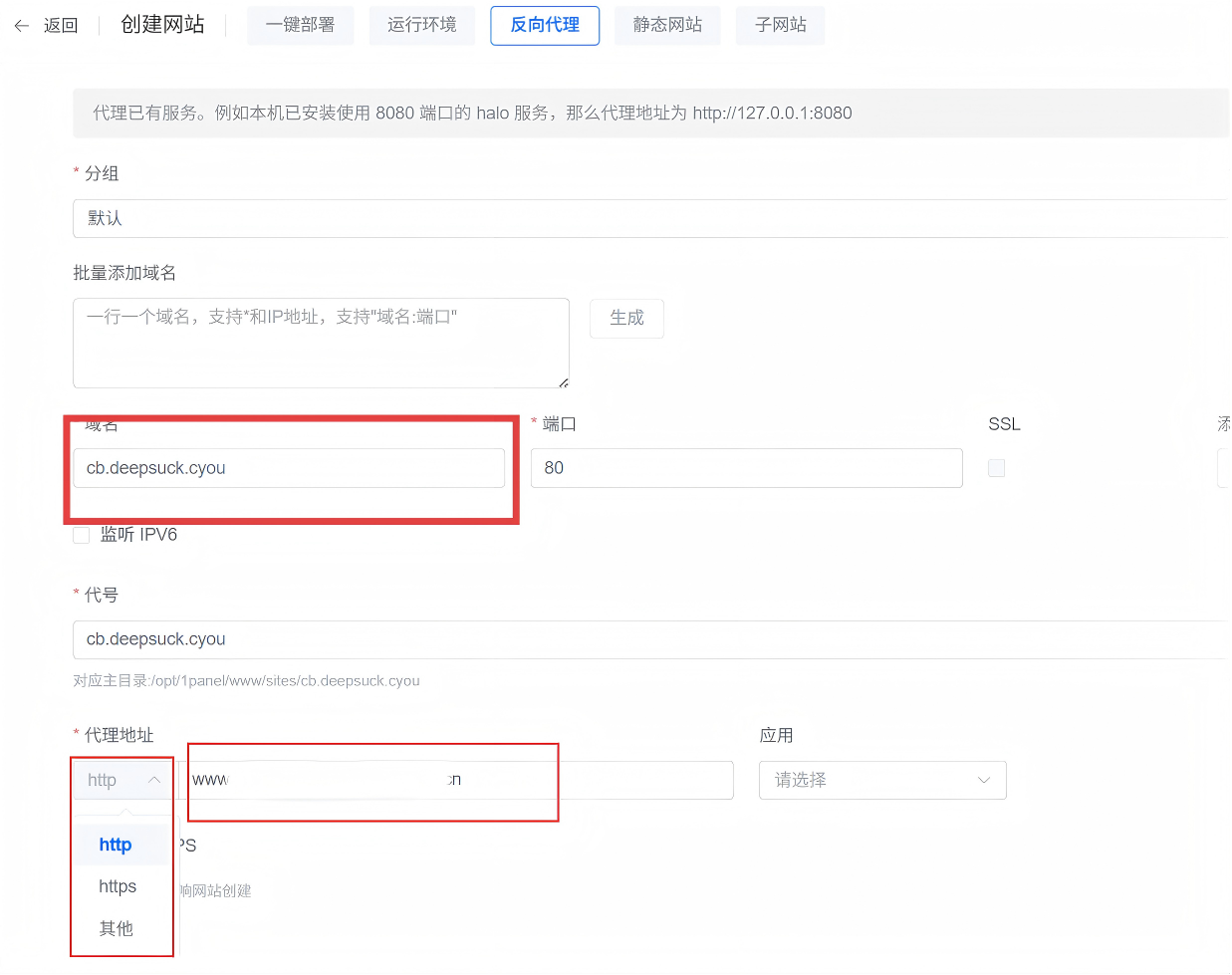
代理地址的协议注意区分 http 和 https。
启用https:
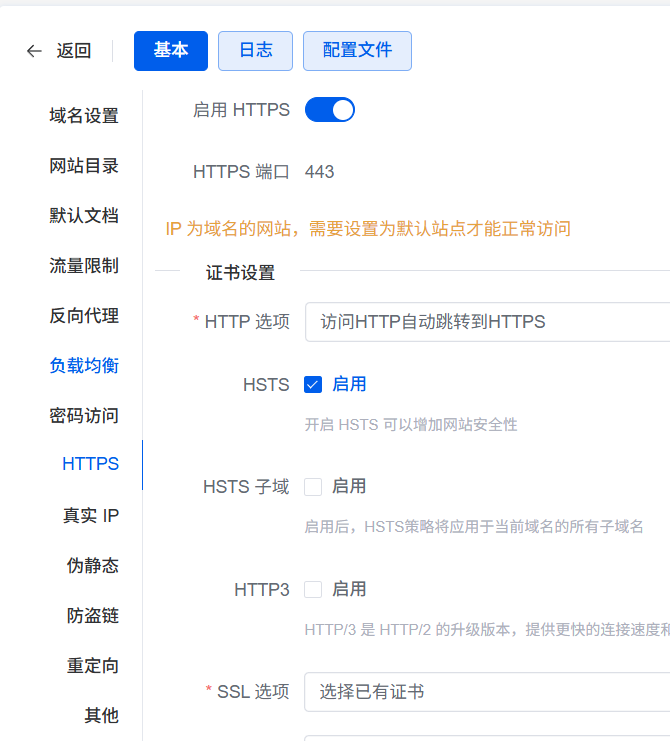
注意,该https只对用户到反代的链接有效,本文里源站是http,反代到源站仍然是不加密的。
最重要的是配置反向代理缓存:
在上图里选择反向代理,点击源文,编辑源文的配置文件:
下面的配置是AI给出的,还是比较好用的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
location ^~ / {
proxy_pass http://www.源网站.cn;
# =========================
# 基础代理头
# =========================
proxy_set_header Host www.源网站.cn;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_http_version 1.1;
proxy_set_header Connection "";
# =========================
# 缓存核心(重点)
# =========================
proxy_cache proxy_cache_zone_of_cb.deepsuck.cyou;
proxy_cache_key $scheme$host$request_uri;
# 缓存时间(拉长,减少回源)
proxy_cache_valid 200 304 301 302 24h;
# =========================
# 防止缓存击穿(非常重要)
# =========================
proxy_cache_lock on;
# 后台更新(用户不等待回源)
proxy_cache_background_update on;
# 源站异常时使用旧缓存(核心保护)
proxy_cache_use_stale error timeout invalid_header updating
http_500 http_502 http_503 http_504;
# =========================
# 调试用(可保留)
# =========================
add_header X-Cache $upstream_cache_status always;
# =========================
# HSTS(安全)
# =========================
add_header Strict-Transport-Security "max-age=31536000" always;
# =========================
# 可选:减少无意义回源头干扰
# =========================
proxy_ignore_headers Set-Cookie Cache-Control Expires;
}
|
其中最重要的是:proxy_cache_valid 200 304 301 302 24h; ,配置了缓存时效为24小时。
缓存时间的缺陷
透过反代访问源站,在文件首次访问后会被缓存。第一次访问的文件,以及缓存过期的会触发回源。
当前设置了较长的缓存时间,24小时。如果缓存的文件被修改,在24小时内是不会更新的。如果老师在实验课的前一天晚上修改了教程,第二天反代返回的依然是旧版的。因此可将缓存时间调小,比如20分钟。
如果调整为20分钟后,间隔太短,缓存很容易失效。缓存失效后,反代并不会主动更新缓存,直到用户主动访问,触发回源。
因此,把缓存时间缩小之后,还要部署脚本,定期主动访问网站,下载网站的每一个文件,才能确保缓存持续更新。
自动化访问网站,及时更新缓存
现在的目标是:当前访问网站,下载网站的所有文件,促使反代更新缓存。
对于一般的静态网页,文件均可以用 wget 命令下载。但是它只能接受单个网页或文件,无法自动遍历网站的子路径。
如: wget https://www.google.com/
wget也可以接受一个文本文件,文本文件里记录要下载的url链接(一行一个),使用下面的命令即可批量下载:
1
|
wget -i clean_urls.txt -O /dev/null -nv
|
clean_urls.txt 记录了要get的url-O /dev/null 重定向get的文件到 /dev/null,避免占用磁盘空间
只要写一个脚本,定期抓取网站的所有url,再推给wget,就能更新缓存。
把提示词给AI,它推荐了 jaeles-project/gospider这个Go项目。最开始推荐别的,不好用,狠狠踩坑了。
这个项目可以选择安装Go模块和Docker,实测Go直接安装更快:
1
|
go install github.com/jaeles-project/gospider@latest
|
安装后,直接调用:
1
|
gospider -s "https://cb.deepsuck.cyou" -o ./ -c 10 -d 5 --sitemap --robots --js --other-source && mv ./cb_deepsuck_cyou gospider_urls.txt
|
gospider的输出是抓到一条url,输出一条,因此要考虑url提取和去重:
1
|
grep -Eo "https://cb.deepsuck.cyou[^ ]+" gospider_urls.txt | sort -u > clean_urls.txt
|
grep -Eo:用正则表达式捕捉以域名开头的所有链接。sort -u:对抓取到的成链接进行去重> clean_urls.txt :把提取好的干净链接保存到一个文本文件里。
然后把准备好的txt文件喂给wget,就能下载了。
源站有pdf课件、一些exe,dmg软件,一般不会去下载的,可以过滤掉
1
|
grep -Eo "https://cb.deepsuck.cyou[^ ]+" gospider_urls.txt | grep -vi "\.pdf$" | grep -vi "\.dmg$"| grep -vi "\.msi$"| grep -vi "\.exe$" | sort -u > clean_urls.txt
|
自动化脚本
一次运行的脚本如下: nano auto-spider.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#!/bin/bash
cd "$(dirname "$0")" || exit 1
# 执行 gospider
/home/ztc/go/bin/gospider -s "https://cb.deepsuck.cyou" -o ./ -c 10 -d 5 --sitemap --robots --js --other-source && mv ./cb_deepsuck_cyou gospider_urls.txt
if [ $? -ne 0 ]; then
echo "❌ gospider 执行失败,退出脚本"
exit 1
fi
# 过滤URL
grep -Eo "https://cb.deepsuck.cyou[^ ]+" gospider_urls.txt | grep -vi "\.pdf$" | grep -vi "\.dmg$" | grep -vi "\.msi$" | grep -vi "\.exe$" | sort -u > clean_urls.txt
if [ $? -ne 0 ]; then
echo "❌ URL 筛选失败或未匹配到结果,退出脚本"
exit 1
fi
# wget 批量请求,并将最后3行写入日志
wget --header="X-Force-Refresh: true" -i clean_urls.txt -O /dev/null -nv 2>&1 | tail -n 3 > wget_last3.log
if [ ${PIPESTATUS[0]} -ne 0 ]; then
echo "⚠️ wget 执行完毕,但存在请求失败的链接(请查看 wget_last3.log)"
else
echo "✅ 全部流程执行成功!"
fi
|
授予可执行权限:sudo chmod +x auto-spider.sh
sudo nano /etc/systemd/system/auto-spider.service :
1
2
3
4
5
6
7
8
|
[Unit]
Description=Run Gospider Auto Script
[Service]
Type=oneshot
User=root
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/root/go/bin"
ExecStart=/bin/bash /home/ztc/gospider_output/auto_spider.sh
|
sudo nano /etc/systemd/system/auto-spider.timer :
1
2
3
4
5
6
7
8
9
10
11
|
[Unit]
Description=Timer for Gospider Auto Script
[Timer]
# 启动后多久开始第一次执行
OnBootSec=1min
# 每次执行完毕后,隔 15 分钟再执行
OnUnitActiveSec=15min
[Install]
WantedBy=timers.target
|
启动systemd:
1
2
|
sudo systemctl daemon-reload
sudo systemctl enable --now auto-spider.timer
|
查看systemd的日志:
1
|
sudo journalctl -u auto-spider.service -f
|
之后网站就能秒开了。